Chico, a spanish dataset
TLDR:
I created a spanish dataset called chico. You can find it through: kaggle.
The code I used can be found in this codeberg repo.
Introduction
Disclaimer:
The dataset is made of public domain text, if you find anything that should not be there, let me know and I will remove it.
I wanted to create a dataset that was focused on spanish. This is my first time scraping some websites and it was a lot of fun.
First of all, I went through three different websites. They were Elejandria, Ganso y Pulpo and finally textos.info.
Scraping in the cases for Elejandria and Ganso y Pulpo was a bit more difficult than textos.info because they did not have an option to read online. The scraping was a bit like the following algorithm:
- 1. Get the catalogue of books.
- 2. Get the link for download of each book.
- 3. Download the books.
Get the catalogue of books
Each one of this websites had their own version of a main catalogue. It was only a matter of going through each one of the catalogue pages and grabbing all of the links that could possibly be books.
For example, this is the code for textos.info:
import requests
from bs4 import BeautifulSoup
links_of_main_pages = set()
for i in range(1, 315):
print("Page",i)
url = "https://www.textos.info/titulos/alfabetico/pag/"
url += str(i)
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "html.parser")
target_h3 = soup.find_all("h3")
for h3 in target_h3:
a = h3.find('a')
if a:
href = a.get("href")
text = a.get_text()
links_of_main_pages.add(href)
else:
print("Failed to retrieve the webpage")
with open('main_book_pages_textos.txt', 'w') as file:
for link in links_of_main_pages:
file.write("https://www.textos.info/" + str(link) + '\n')
Getting the link for downloading each book
This is a step that I took for Elejandria and GP (Ganso y Pulpo) because they had a different page for each thing.
links_of_downloads = set()
...
for i, url in enumerate(urls):
print(i, end=" ")
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "html.parser")
links = soup.find_all("a")
for link in links:
href = link.get("href")
text = link.text
if "/descargas/" in href:
links_of_downloads.add(href)
else:
print("Failed to retrieve the webpage")
Downloading the books
I created a simple bash script that uses wgetfor this. I think, there are a lot more elegant ways to do this, but it worked for Ganso y Pulpo and Elejandria. For textos.info I got the information directly from their website because they have an option to read the book online.
#!/bin/bash
# The .txt list of links ready to be downloaded
input_file="press_download_links.txt"
# Check if the input file exists
if [ ! -f "$input_file" ]; then
echo "Input file '$input_file' not found."
exit 1
fi
while IFS= read -r url; do
if [ -z "$url" ] || [ "${url:0:1}" = "#" ]; then
continue
fi
wget "$url"
echo "Downloaded: $url"
echo "---------------------"
done < "$input_file"
echo "All downloads completed."
Parsing epubs
In the case of ganso y pulpo and elejandria I had to parse epubs. I did not know that epub in the back was actually just a zip file. It makes sense now that I have worked with it.
The main function to grab the text of each epub was the following:
def get_content(epub_path):
file_content = []
with zipfile.ZipFile(epub_path, 'r') as epub:
for filename in epub.namelist():
if 'texto' in filename or filename.endswith('.html') or filename.endswith('.xhtml'):
html_file = epub.open(filename)
html_content = html_file.read()
html_content = html_content.decode('utf-8')
soup = BeautifulSoup(html_content, 'html.parser')
paragraphs = soup.find_all('p')
title_chapter = soup.find('title')
if title_chapter:
file_content.append(title_chapter.get_text())
file_content.append('\n')
for p in paragraphs:
file_content.append(p.get_text())
file_content.append('\n\n')
html_file.close()
return file_content
I normally grabbed the titles as follows for the epubs from ganso y pulpo.
def get_title(epub_path):
with zipfile.ZipFile(epub_path, 'r') as epub:
for filename in epub.namelist():
if 'texto' in filename:
html_file = epub.open(filename)
html_content = html_file.read()
html_content = html_content.decode('utf-8')
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.title
if title:
return title.text
html_file.close()
Problems parsing epubs
I had a lot of problems with the epubs of Elejandria. They did not follow in their entirety the same format. I gave up on getting the title and if it failed to grab the specific title I randomized a title for it with the following function.
def get_random_string(): string_length = 20 letters_and_digits = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789" return ''.join([random.choice(letters_and_digits) for i in range(string_length)])
There where some epubs that I could not parse. They where basically empty files, that followed the same, pattern, so I used a simple bash script to remove them.
find . -type f | grep -E '/[a-zA-Z0-9]{20}\.txt$' | while read -r filename; do
# Get the size of the file in bytes
file_size=$(stat -c %s "$filename")
# Compare file size to 26 bytes
if [ "$file_size" -lt 26 ]; then
echo "File $filename is less than 26 bytes:"
cat "$filename"
rm "$filename"
fi
done
Putting it all together
I had a ton of .txt files. I decided to put all of this files into a single .csv file. I did this in a small jupyter notebook.
def get_titles_and_contents(path: Path, path_2_remove: str):
titles = []
contents = []
for item in path.iterdir():
with open(item, 'r') as file:
contents.append(file.read())
titles.append(str(item).replace(path_2_remove,''))
return titles, contents
With this you can create a pandas dataframe.
df = pd.DataFrame({'titles':titles,'contents':contents})
But, I forgot to remove the .txt part from the titles, so I created another small function to apply.
def remove_txt_extension(text):
return text.replace('.txt', '')
df['titles'] = df['titles'].apply(remove_txt_extension)
Finally, write it to a csv.
df.to_csv('./chico.csv', index=False)
A Tiny Exploratory Data Analysis
There are in total 9 215 files in the dataset. I wanted to get it to 10 000, but it is close enough.
There are a total of 129 233 779 million words throughout all of the data.
The biggest file has 1 234 670 words
Almost all of the text are shorter.
In general, there are a lot of shorter texts as the following histogram shows.
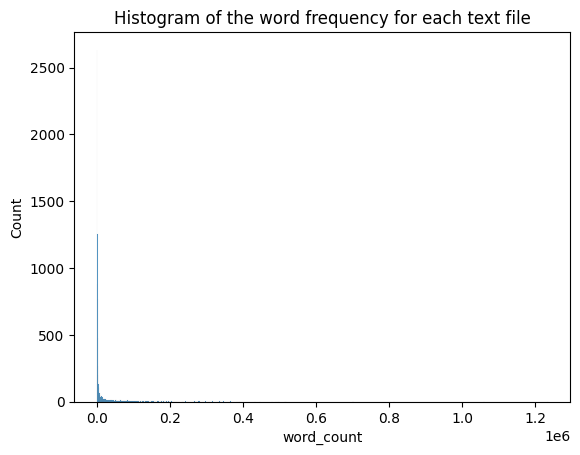
In this histogram there seems to be a lot of text that are almost in zero. But if we zoom a bit in, that is not the case.
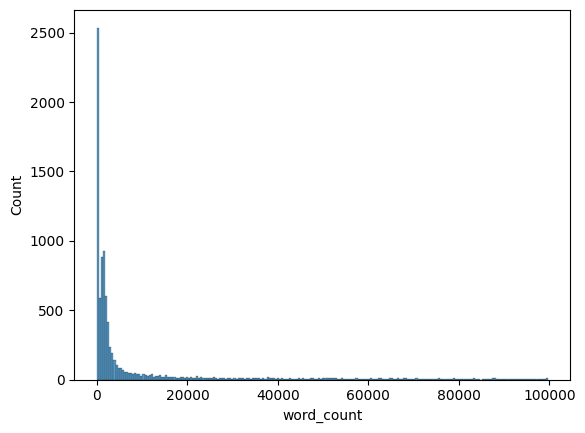
For a more detailed EDA, you can check the full EDA through this Kaggle notebook.
Conclusion
I really liked creating this small dataset. I knew that scraping was a thing and I wanted to learn how to do it.
I was expecting that so many words would occupy more space, but at only 773MB it impressed me that it did not take that much space.
If you ever end up using the dataset, email your findings, I want to see what people do with it.
If you want to cite the dataset, use the following blurb:
@misc{
author = {Santiago Pedroza},
title = {chico},
howpublished = {Kaggle},
year = {2023},
url = {https://www.kaggle.com/datasets/santiagopedroza/elchico},
}